Project Report
Motivations
Nowadays, children care center become a worldwide popular topic due to increasing working parents. Most working parents send their child to children care center during work time. In a high demand of request, selecting a safe and healthy children care environment is important. However, some children care center still has severe safety and hygiene issues which NYC government classify them as violation according to their severity level. In this research, we are trying to investigate the violation in children care center in NYC based on the NYC Open data set for predicting occurrence of violation based on multiple socioeconomic variables.
For further illustrate connection between selected socioeconomic variables and violation occurrence, we construct a logistic regression model to analysis significance of each variable in predicting violation along with a map displaying violation occurrence based on zip code in New York city.
Initial Questions
Our initial question focuses on how socioeconomics factors are related to childcare center violation in New York. We investigated multiple factors such as borough and childcare type to create a more lucid analysis of occurrence of childcare violation. Specifically, we evaluates borough with high occurrence of violation and childcare types for which most violation occurs. Further details related to the study will be presented in other parts of the websites.
Data
Our data was downloaded from NYC Open Data on November 25th.
This dataset contains a list of all inspections conducted and any associated violations at active, city-regulated, center-based child care programs and summer camps over the past 3 years. The violations are pre-adjudicated. Violations that are subject to potential penalties (fines) are submitted to NYC Office of Administrative Trials and Hearing where they are adjudicated as either sustained/upheld or dismissed. The dataset also contains additional information on the programs, including license information. For more information on child care in NYC visit: https://www1.nyc.gov/site/doh/services/child-care.page.
There are 26397 observations and 34 variables in our raw dataset.
However, we are only interested in the childcare centers that are currently permitted. Hence, we filter the variables to include currently permitted Children Care Center.
For the next step,we remove the useless variables: legal_name, building, street, phone, permit_number, permid_expiration, day care id, url, date_permitted, actual. We then dropped NAs for certain variables. Noted that, for violation category, NA represent NO VIOLATION. So we mutate this column and replace NA with “NO VIOLATION” for clarification. At this point, we found out that for child_care_type == camping (which can also be identified as age rang == “0 YEARS - 16 YEARS”), we only have 3 data points that are valid. Considering the sample size is too small, we decided to exclude this childcare type from our analysis.
The cleand dataset have 14,348 observations and 24 variables.
library(tidyverse)
library(patchwork)
library(plotly)
library(haven)
library(viridis)## Loading required package: viridisLitelibrary(data.table)
options(
ggplot2.continuous.colour = "viridis",
ggplot2.continuous.fill = "viridis"
)
theme_set(theme_minimal() + theme(legend.position = "bottom",
legend.text = element_text(size = 8),
legend.title = element_text(size = 9),
legend.key.size = unit(.5,"line")))
options(
ggplot2.continuous.colour = "viridis",
ggplot2.continuous.fill = "viridis"
)
scale_colour_discrete = scale_colour_viridis_d
scale_fill_discrete = scale_fill_viridis_dExploratory Data Analysis
In order to illustrate association between age range, program type and violation category. We plotted multiple graphs below.
### Age Range vs Violation Category
Childcare_center %>%
group_by(age_range) %>%
count(violation_category) %>%
ggplot(aes(fill =violation_category, x=age_range,y = n))+
geom_bar(position = "dodge", stat = "identity")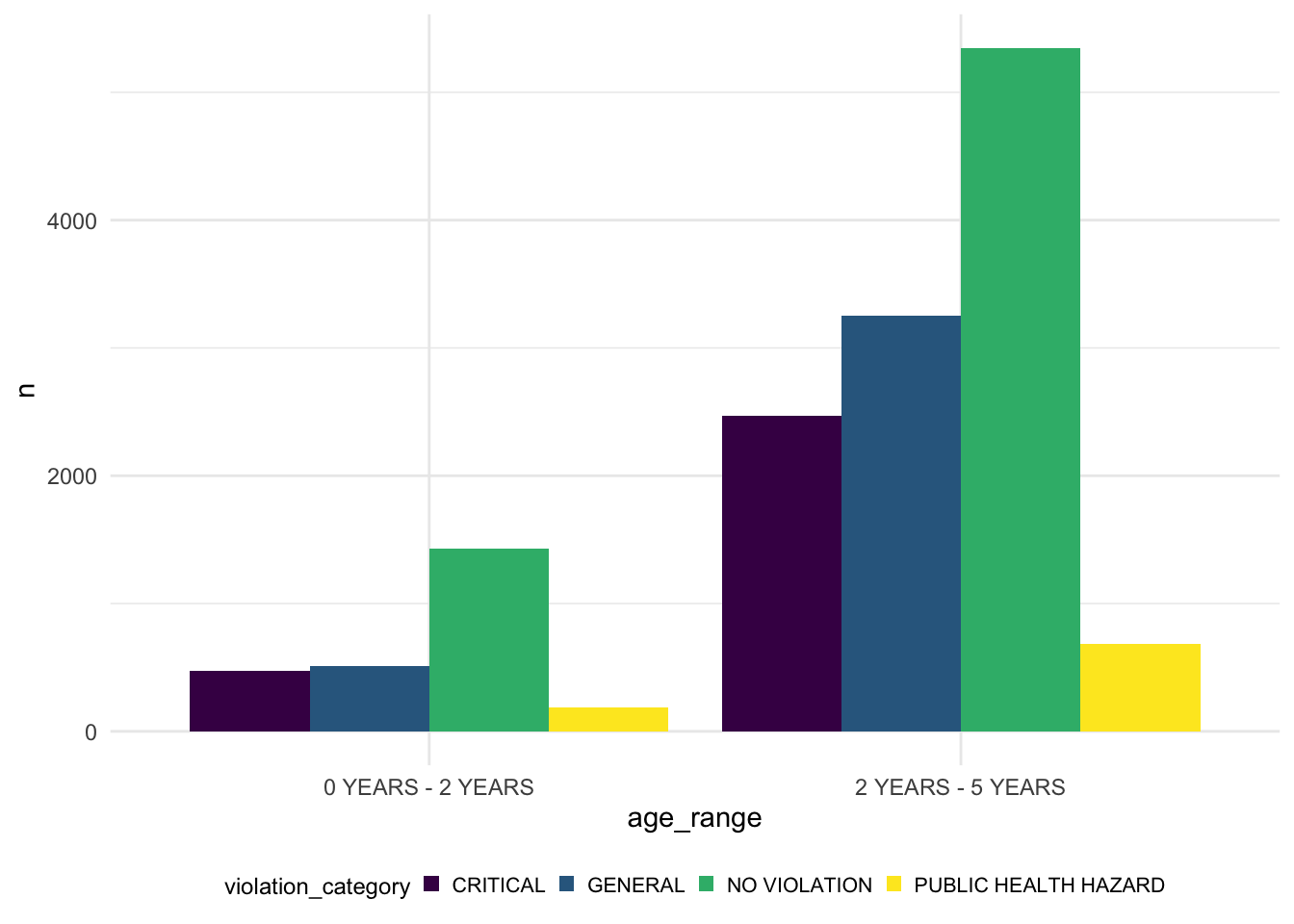
Age range is the same as the program type violation.(graph below)
### Program Type vs Violation Category
Childcare_center %>%
group_by(program_type) %>%
count(violation_category) %>%
ggplot(aes(fill =violation_category, x=program_type,y = n))+
geom_bar(position = "dodge", stat = "identity")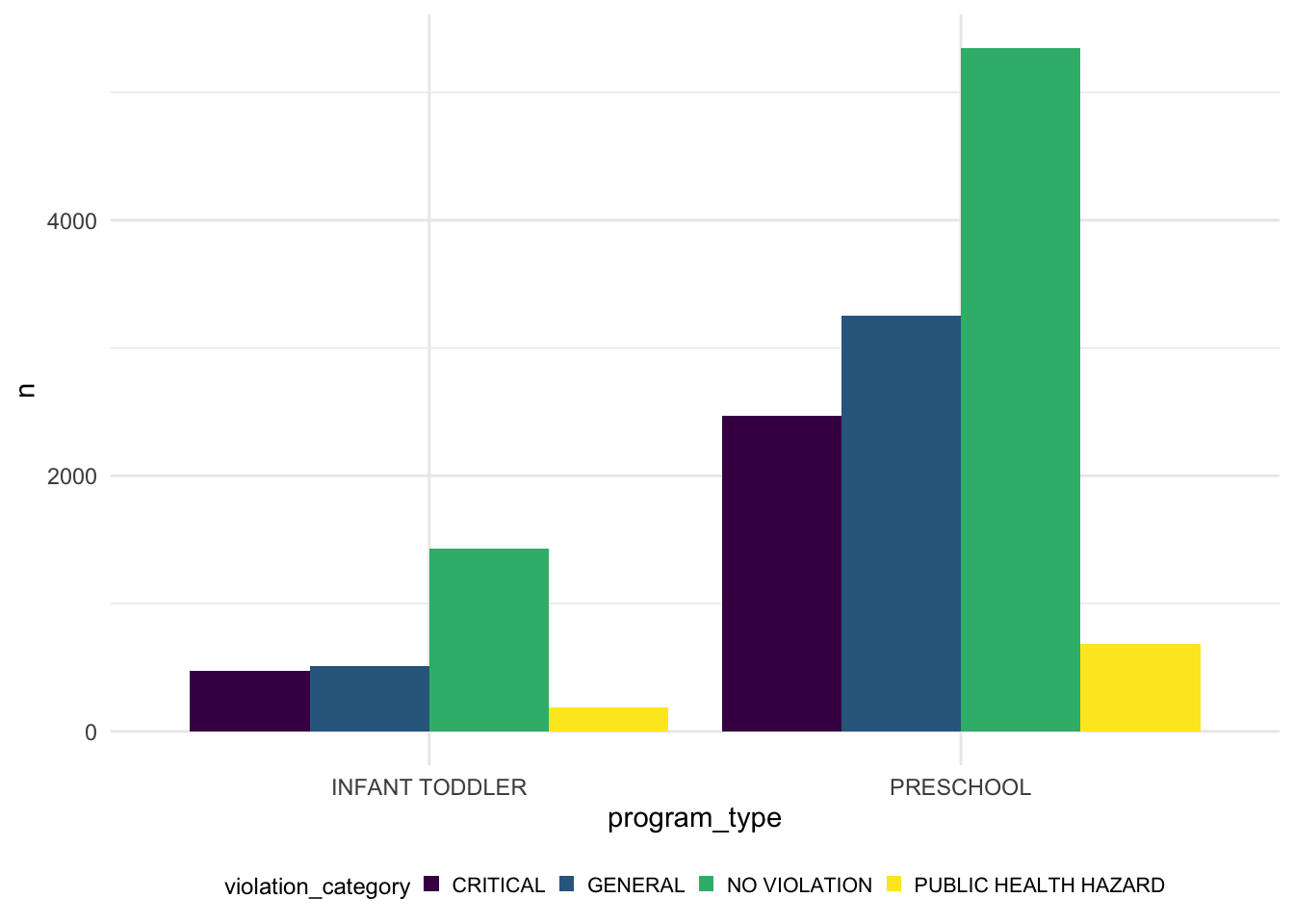
After analysing the data we found that the age-range and program type relationship is the same. Infant school is for 0-2 years kids and preschool is for 0-5 years kids. The graph above showing the relationship between the program type (Preschool&Infant Toddler) and the violation category cases(Critial, General, No Violation and Public Health Hazrd). As we can see from the graph, preschool has a higher violation cases in the categoy “public health hazard”, “general” and “critical” than the Infant todddler program type. And in three violation categories, the “general” cases is higher then the other two.
Borough is another significant geographical factor for analyzing violation. We examine connection between borough and violations.
We examined the inspection categories of child care centers in different areas of New York that had records of violations,We found that the categories of inspection are divided into four major categories, which are Compliance Inspection of Open Violations, Initial Annual Inspection, Lead Based Paint or Lead in Water Inspection, Monitoring Inspection Non-Routine.
### Borough vs. Inspection summary result
borough_inspec_summmary<-
Childcare_center%>%
select(borough,inspection_summary_result)%>%
drop_na(inspection_summary_result)%>%
group_by(borough,inspection_summary_result)%>%
summarise(
n_obs=n()
)%>%
mutate(
general_category=case_when(
inspection_summary_result %like% "^Compliance Inspection of Open Violations" ~"Compliance Inspection of Open Violations",
inspection_summary_result %like% "^Initial Annual Inspection" ~"Initial Annual Inspection",
inspection_summary_result %like% "^Lead Based Paint or Lead in Water Inspection" ~"Lead Based Paint or Lead in Water Inspection",
inspection_summary_result %like% "^Monitoring Inspection Non-Routine" ~"Monitoring Inspection Non-Routine")
)
head(borough_inspec_summmary)## # A tibble: 6 × 4
## # Groups: borough [1]
## borough inspection_summary_result n_obs gener…¹
## <chr> <chr> <int> <chr>
## 1 BRONX Compliance Inspection of Open Violations - Passed inspe… 96 Compli…
## 2 BRONX Compliance Inspection of Open Violations - Previously c… 29 Compli…
## 3 BRONX Compliance Inspection of Open Violations - Previously c… 3 Compli…
## 4 BRONX Compliance Inspection of Open Violations - Reinspection… 48 Compli…
## 5 BRONX Compliance Inspection of Open Violations - Reinspection… 94 Compli…
## 6 BRONX Compliance Inspection of Open Violations - Reinspection… 92 Compli…
## # … with abbreviated variable name ¹general_categoryTo better examine the number of violations in different types of inspections at child care centers in different borough of New York, we categorized and summarise the records of violation inspections by borough and type of inspection.
### Borough group by General Category
borough_inspec_general_sumary<-
borough_inspec_summmary%>%
group_by(borough,general_category)%>%
summarise(
n_obs=sum(n_obs)
) %>%
arrange(desc(n_obs))
borough_inspec_general_sumary## # A tibble: 19 × 3
## # Groups: borough [5]
## borough general_category n_obs
## <chr> <chr> <int>
## 1 QUEENS Initial Annual Inspection 3208
## 2 BROOKLYN Initial Annual Inspection 2852
## 3 MANHATTAN Initial Annual Inspection 1687
## 4 BRONX Initial Annual Inspection 1586
## 5 BRONX Compliance Inspection of Open Violations 521
## 6 MANHATTAN Monitoring Inspection Non-Routine 468
## 7 BROOKLYN Compliance Inspection of Open Violations 457
## 8 STATEN ISLAND Initial Annual Inspection 401
## 9 QUEENS Compliance Inspection of Open Violations 390
## 10 BROOKLYN Monitoring Inspection Non-Routine 301
## 11 BRONX Monitoring Inspection Non-Routine 284
## 12 QUEENS Monitoring Inspection Non-Routine 249
## 13 STATEN ISLAND Monitoring Inspection Non-Routine 141
## 14 MANHATTAN Compliance Inspection of Open Violations 68
## 15 STATEN ISLAND Compliance Inspection of Open Violations 32
## 16 BRONX Lead Based Paint or Lead in Water Inspection 10
## 17 BROOKLYN Lead Based Paint or Lead in Water Inspection 10
## 18 MANHATTAN Lead Based Paint or Lead in Water Inspection 6
## 19 QUEENS Lead Based Paint or Lead in Water Inspection 5We also created the following chart by type of inspection and the number of violations recorded. We found that New York’s child care centers had the highest number of violations in the intial annual inspection, far exceeding the other three types of violations combined, with the Queen’s district having the highest number of violations at 3,600 records. In contrast, Lead Based Paint or Lead in Water Inspection had the least number of violations, with bronx having ten records, Brooklyn having eleven records, Manhattan having six records, queens having five records, and staten island not even having this type of record.
borough_inspec_general_sumary_plot_all<-
borough_inspec_general_sumary%>%
ggplot(aes(x=general_category,y=n_obs),)+
geom_bar(aes(fill = borough), stat = "identity")+
theme(axis.text.x = element_text(size=10, angle=45, hjust = 1))+
labs(y="number of violations",title="Inspection categories vs. Borough",x="inspection categories")
ggplotly(borough_inspec_general_sumary_plot_all)### General Type vs Borough
inspec_general_borough_sumary<-
borough_inspec_summmary%>%
group_by(general_category,borough)%>%
summarise(
n_obs=sum(n_obs)
) %>%
arrange(desc(n_obs))
inspec_general_borough_sumary## # A tibble: 19 × 3
## # Groups: general_category [4]
## general_category borough n_obs
## <chr> <chr> <int>
## 1 Initial Annual Inspection QUEENS 3208
## 2 Initial Annual Inspection BROOKLYN 2852
## 3 Initial Annual Inspection MANHATTAN 1687
## 4 Initial Annual Inspection BRONX 1586
## 5 Compliance Inspection of Open Violations BRONX 521
## 6 Monitoring Inspection Non-Routine MANHATTAN 468
## 7 Compliance Inspection of Open Violations BROOKLYN 457
## 8 Initial Annual Inspection STATEN ISLAND 401
## 9 Compliance Inspection of Open Violations QUEENS 390
## 10 Monitoring Inspection Non-Routine BROOKLYN 301
## 11 Monitoring Inspection Non-Routine BRONX 284
## 12 Monitoring Inspection Non-Routine QUEENS 249
## 13 Monitoring Inspection Non-Routine STATEN ISLAND 141
## 14 Compliance Inspection of Open Violations MANHATTAN 68
## 15 Compliance Inspection of Open Violations STATEN ISLAND 32
## 16 Lead Based Paint or Lead in Water Inspection BRONX 10
## 17 Lead Based Paint or Lead in Water Inspection BROOKLYN 10
## 18 Lead Based Paint or Lead in Water Inspection MANHATTAN 6
## 19 Lead Based Paint or Lead in Water Inspection QUEENS 5The following chart can better understand the violation situation of different Boroughs in New York. We can see that queens has the most violation records, Brooklyn has less violation records than queens but still far more than bronx and Manhattan, and staten island has the least violation records.
violation_borough_sumary_all<-
inspec_general_borough_sumary%>%
ggplot(aes(x=borough,y=n_obs))+
geom_bar(aes(fill=general_category),stat = "identity")+
theme(axis.text.x = element_text(size=10, angle=45, hjust = 1))+
labs(y="number of violations",title="Borough vs.Inspection categories",x="borough")
ggplotly(violation_borough_sumary_all)### Borough vs Violation Category
Childcare_center %>%
mutate(violation_category = ifelse(is.na(violation_category), "NO VIOLATION", violation_category)) %>%
group_by(borough, age_range) %>%
count(violation_category) %>%
ggplot(aes(fill =violation_category, x=borough,y = n))+
geom_bar(position = "dodge", stat = "identity")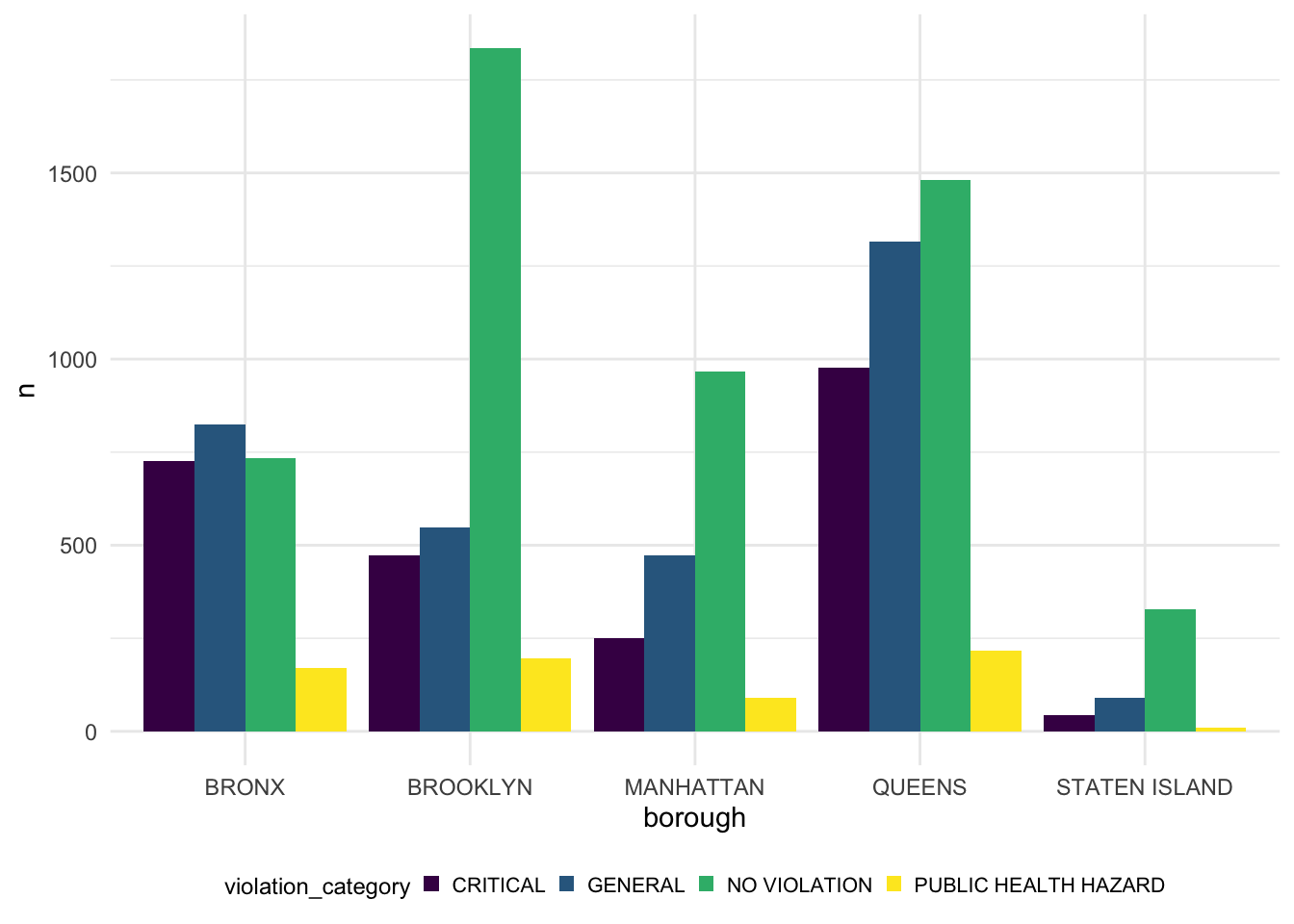
The graph above showing the relationship between the borough and the cases of violation in each category. From the grpah we can see, queens is the borough whihc has the most violation cases in all three categories and staten island has the least violation cases in all three categories. And in Brooklyn, it has the highest no violation cases.
# try
try = Childcare_center %>%
mutate(violation_category = ifelse(is.na(violation_category), "NO VIOLATION", violation_category)) %>%
select(borough,program_type,violation_category)%>%
filter(program_type!="CAMP")%>%
group_by(borough, program_type,violation_category) %>%
summarise(
n_obs=n())%>%
ggplot(aes(x = borough, y = n_obs, fill = violation_category))+
geom_bar(stat="identity", width = 0.5, position = "dodge")+
facet_grid(. ~ program_type) +
theme_bw() +
theme(axis.text.x = element_text(angle = 28),axis.text = element_text(size = 5))
ggplotly(try) The graph above is showing the relationship between borough and the number of violation category count in two different program types. The borough can separate the five parts “Bronx”, “Brooklyn”, “Manhattan”, “Staten Island” and “Queens”. Violation category can be separate “Critical”, “General”, “No Violation” and “Public Helath Hazard”. Combining two graphs, pre school will have a higher violation cases in each borough in overall. In infant toddler, Brooklyn is the borough that having the largest violation cases.But in preschool, queens is the borough that having the largest cases. Staten island has the smallest cases in both preschool and infant toddler. Footer
We are also interested in the relationship between maximum capacity and child care type.
We can see from the following boxplot that the distributions of maximum capacity in preschool and Infants / Toddlers are significantly different. Overall, Preschool has higher maximum capacity than Infants/Toddlers, and the range of capicity is also wider than it is in the Infants/Toddlers.The max maximum capacity in childcare center is 371, while the max maximum capacity in Infants/Toddlers is 135. Hence, when we analyze the relationship between violation category and maximum capacity, we should stratify by childcare type and then compare the relationship within each group.
plotly_capacity_type = Childcare_center %>%
group_by(violation_category, maximum_capacity, child_care_type) %>%
plot_ly(y = ~maximum_capacity, color = ~child_care_type, type = "box", colors = "viridis")
plotly_capacity_typeWe then examine whether there is connection between maximum capacity and violation. Since the maximum capacity in different child care types are different, we display the distribution of maximum capacity vs violation category by child care type.
We can conclude from the plot that there is no significant difference between the distribution of maximum capacity for each violation category. Besides, there are many outliers in each groups, which means the variance of maximum capacity is large. This may affect our analysis result.
boxplot_capacity = Childcare_center %>%
mutate(violation_category = ifelse( is.na(violation_category), "NO VIOLATION", violation_category)) %>%
group_by(violation_category, maximum_capacity, child_care_type) %>%
ggplot(aes(x = violation_category, y = maximum_capacity, color = child_care_type)) +
geom_boxplot() +
labs(
x = "Violation category",
y = "Maximum capacity",
color = ""
) +
theme(legend.position = "bottom")
boxplot_capacity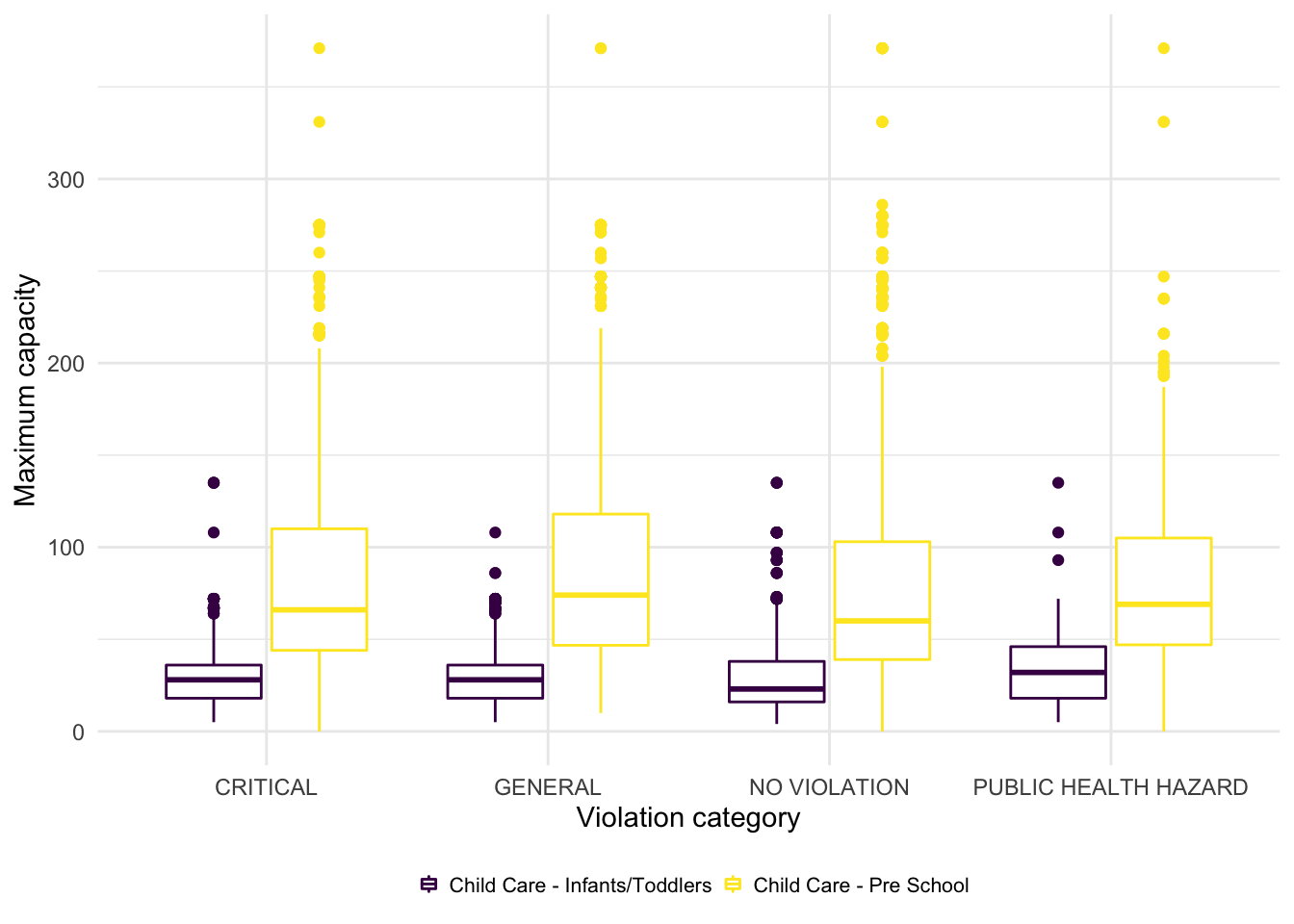
To further analyze the association, we set maximum capacity less than its median as small center, and larger and equal than its median as larger center by child care type, and then compare the frequecny of violation types.
(1). Pre School
We can see from the frequency bar chart that pre schools with larger maximum capacity are more likely to violate related rules: the frequecnies are higher in all violation categories. In contract, pre schools with smaller maximum capacity have more chance of no violation.
(2). Infants/Toddlers
The frequency of violation is higher in Infants/Toddlers with larger maximum capacity; and the frequency of no violation is higher in Infants/Toddlers with smaller maximum capacity. The result suggests the larger childcare centers are more likely to have violations.
library(patchwork)
bar_max_cap1 = Childcare_center %>%
mutate(violation_category = ifelse( is.na(violation_category), "NO VIOLATION", violation_category),
maximum_capacity_group = ifelse(maximum_capacity<66, "small", "large")) %>%
filter(child_care_type == "Child Care - Pre School") %>%
group_by(violation_category, maximum_capacity_group) %>%
summarise(count = n()) %>%
ggplot(aes(x = violation_category, y = count, fill = maximum_capacity_group)) +
geom_bar(stat="identity", position=position_dodge()) +
geom_text(aes(label=count), vjust=1.6, color="white",
position = position_dodge(0.9), size=3.5)+
labs(
x = "Violation Category",
y = "Frequency",
title = "Pre School",
fill = "Group"
) +
theme(legend.position = "bottom", axis.text.x = element_text(size=10, angle=45, hjust = 1))
bar_max_cap2 = Childcare_center %>%
mutate(violation_category = ifelse( is.na(violation_category), "NO VIOLATION", violation_category),
maximum_capacity_group = ifelse(maximum_capacity<26, "small", "large")) %>%
filter(child_care_type == "Child Care - Infants/Toddlers") %>%
group_by(violation_category, maximum_capacity_group) %>%
summarise(count = n()) %>%
ggplot(aes(x = violation_category, y = count, fill = maximum_capacity_group)) +
geom_bar(stat="identity", position=position_dodge()) +
geom_text(aes(label=count), vjust=1.6, color="white",
position = position_dodge(0.9), size=3.5)+
labs(
x = "Violation Category",
y = "Frequency",
title = "Infants/Toddlers",
fill = "Group"
) +
theme(legend.position = "bottom", axis.text.x = element_text(size=10, angle=45, hjust = 1))
bar_max_cap1 + bar_max_cap2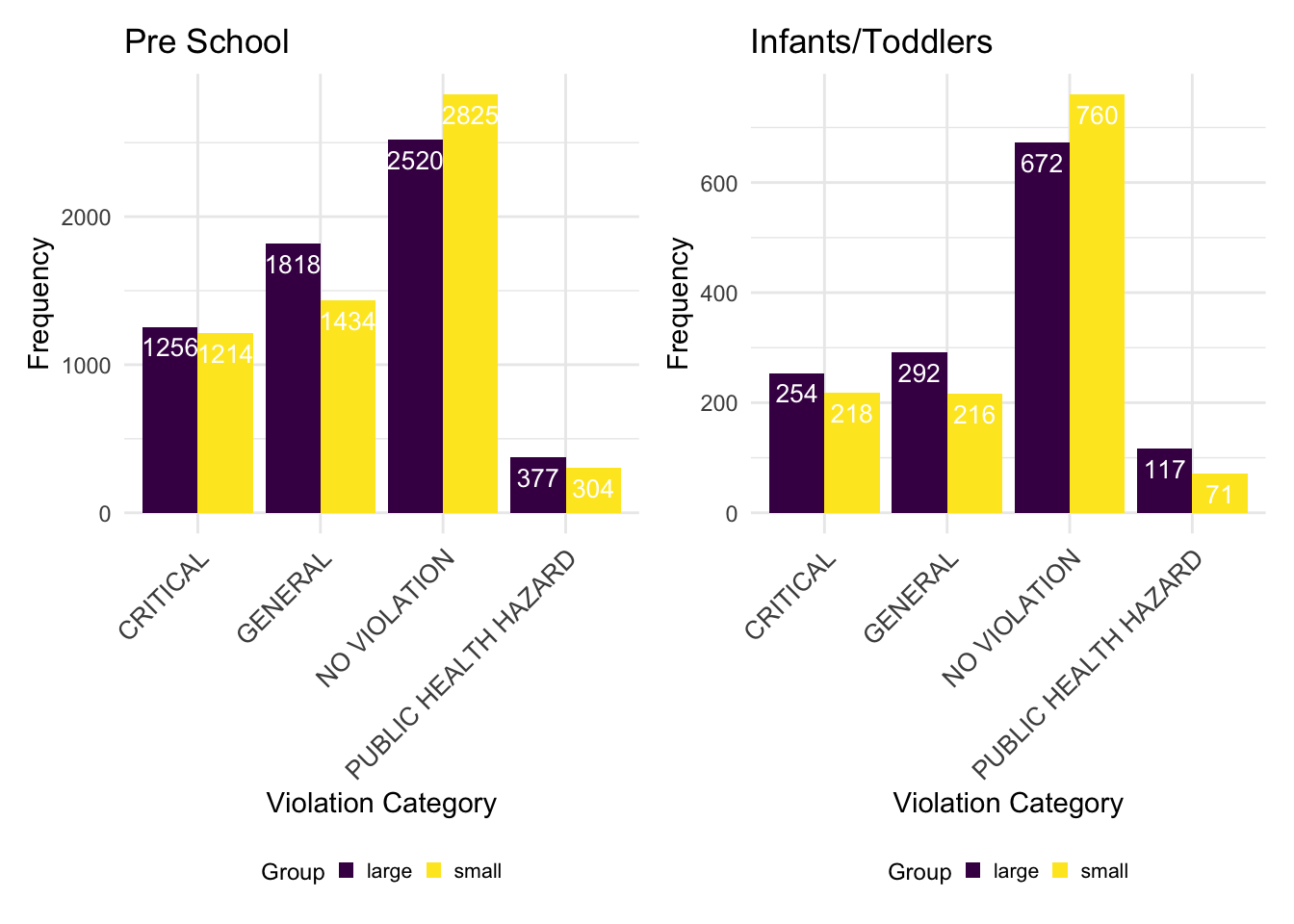
We then analyzed the relationship between total educational workers and violation category. As we can see, there’s no significant difference between the distribution of total education workers in each violation categories.
boxplot_worker = Childcare_center %>%
group_by(violation_category, total_educational_workers, child_care_type) %>%
mutate(violation_category = ifelse( is.na(violation_category), "NO VIOLATION", violation_category)) %>%
ggplot(aes(x =violation_category , y = total_educational_workers , color = child_care_type)) +
geom_boxplot() +
labs(
x = "Violation category",
y = "Total educational workers",
color = ""
) +
theme(legend.position = "bottom")
boxplot_worker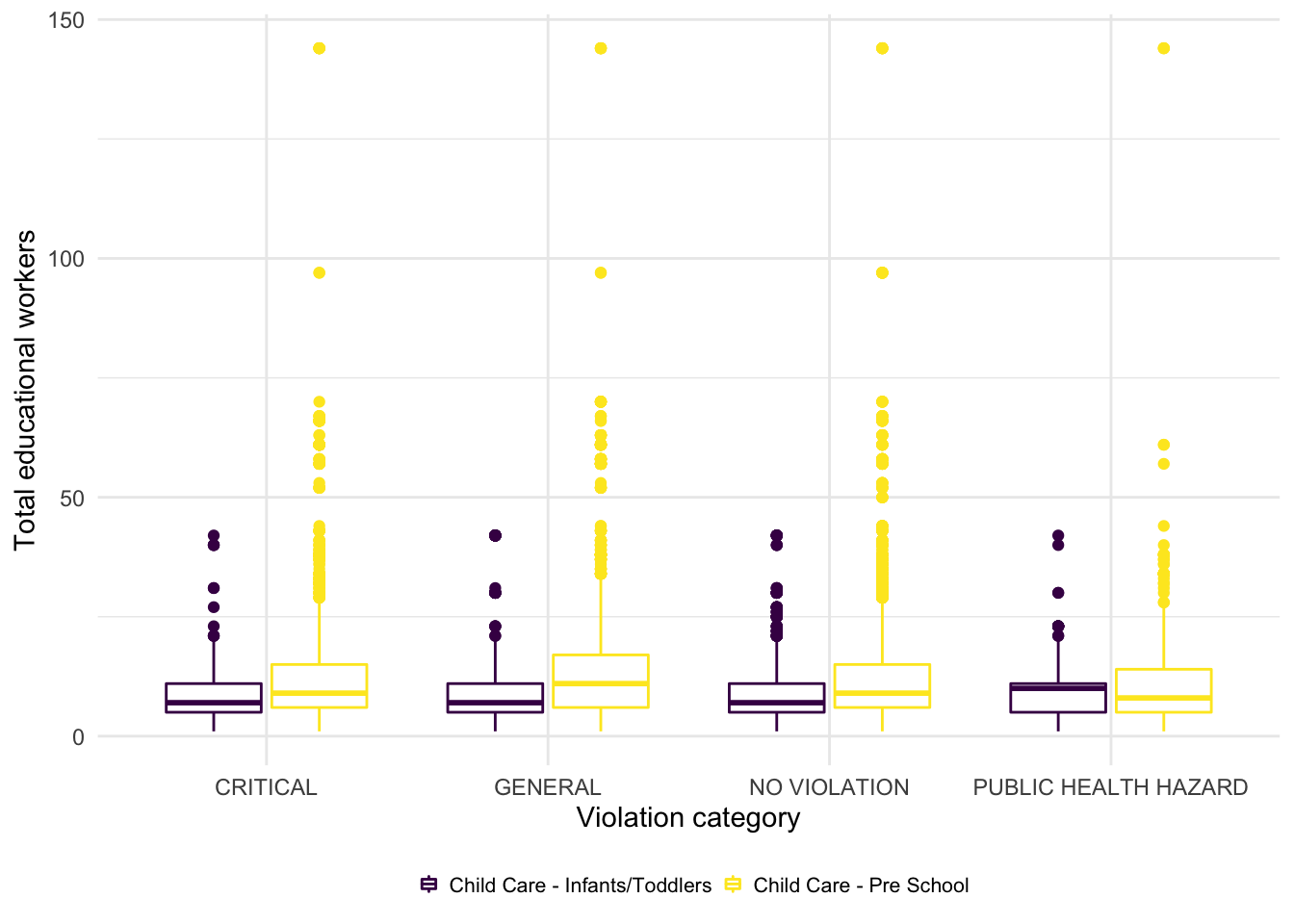
Since total educational workers is not significantly associated with violation cetagory, I wonder if the average works per child is a great predictor. Hence, I divided maximum capacity by total educational workers and get average workers per child. As we can see, there’s also no significant different within each child care type. But the educational workers per child is higher in Infants/Toddlers than it is in Pre school.
plotly_capacity_type = Childcare_center %>%
mutate(workers_per_child = total_educational_workers/maximum_capacity) %>%
group_by(workers_per_child, violation_category, child_care_type) %>%
plot_ly(y = ~workers_per_child, type = "box", x = ~violation_category, color = ~child_care_type, colors = "viridis") %>%
layout(boxmode = "group")
plotly_capacity_typeAdditional Analysis
Formal statistical analyses are also performed to see if there’s statistical significance between our predictors and violation category.
Chi-squared test and ANOVA are conducted to examine significance of variable borough and program types for predicting violation occurrence.
Chi-Square test - Borough vs Violation Category
program type and violation category to test the association between the two variables.
H0:There is no association between program type and violation category
H1:There is association between program type and violation category
tbl1=table(Childcare_center$borough,Childcare_center$violation_category)
chisq.test(tbl1)##
## Pearson's Chi-squared test
##
## data: tbl1
## X-squared = 999.29, df = 12, p-value < 2.2e-16chisq.test(tbl1)%>%
broom::tidy() %>%
knitr::kable()| statistic | p.value | parameter | method |
|---|---|---|---|
| 999.2946 | 0 | 12 | Pearson’s Chi-squared test |
There is significant relationship between program type and violation category suggested by the computed p-value much lower than 0.05
Chi-Square test - Program Types vs Violation Category
We conducted a chi-squared test between childcare type and violation category to test the association between the two variables.
H0:There is no association between childcare type and violation category
H1:There is association between childcare type and violation category
tbl2=table(Childcare_center$child_care_type,Childcare_center$violation_category)
chisq.test(tbl2)##
## Pearson's Chi-squared test
##
## data: tbl2
## X-squared = 111.01, df = 3, p-value < 2.2e-16chisq.test(tbl2) %>%
broom::tidy() %>%
knitr::kable()| statistic | p.value | parameter | method |
|---|---|---|---|
| 111.0138 | 0 | 3 | Pearson’s Chi-squared test |
There is significant relationship between childcare type and violation category suggested by the computed p-value much lower than 0.05
ANOVA Test - Borough and Violation
We want to examining the relationship between the mean of total violation event (GENERAL+CRITICAL+PUBLIC HEALTH HAZARD) and borough. The frequency of violation events were separated by five boroughs (Manhattan, Brooklyn, Queens, Staten Island, Bronx).
H0: The mean of violation are not different across borough
H1: The mean of violation are different across borough
clean_1 = children_center<-
raw_data%>%
janitor::clean_names()%>%
mutate(
center_name=tolower(center_name),
center_name=gsub('[[:punct:] ]+',' ',center_name),
center_name=gsub(" ","",center_name),
center_name=gsub("llc","",center_name),
center_name=gsub("inc","",center_name),
center_name=gsub("th","",center_name),
center_name=gsub("school","",center_name),
center_name=gsub("center","",center_name),
center_name=gsub("ctr","",center_name)
)%>%
filter(status=="Permitted") %>%
mutate(borough = as.factor(borough), program_type = as.factor(program_type)) %>%
filter(violation_category != "NO VIOLATION") %>%
mutate(violation_category = "VIOLATION") %>%
group_by(center_name,borough) %>%
count()
fit = lm(n~ borough, data = clean_1)
anova(fit) %>%
knitr::kable(caption = "One way anova of Violation frequency and Brough")| Df | Sum Sq | Mean Sq | F value | Pr(>F) | |
|---|---|---|---|---|---|
| borough | 4 | 15688.56 | 3922.141 | 25.89965 | 0 |
| Residuals | 985 | 149164.49 | 151.436 | NA | NA |
The p-value is very small(p<0.05). We reject the null hypothesis and saying that there is enough evidence the mean of violation are different across borough.
After validating the significance of age range and program type, we constructed a logistics regression model for predicting violation occurrence.
Logistic Regression
We also want to build a model to predict whether a childcare facility will violate or not.
Our model is shown below:
# New dataset for modelling
childcare_model <- Childcare_center %>%
mutate(violation_category = ifelse(violation_category == "NO VIOLATION", 0, 1),
borough = as.factor(borough)) %>% # 0 is no liolation, 1 is with violation
select(borough,child_care_type,total_educational_workers,maximum_capacity, violation_category)
# fit logistic reg
logistic_model = childcare_model %>%
glm(violation_category ~ borough + child_care_type + maximum_capacity, data = ., family = binomial()) %>%
broom::tidy() %>%
knitr::kable(caption = "Effect of Predictors on Violation Status")
logistic_model| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 0.4692795 | 0.0559961 | 8.380571 | 0.0000000 |
| boroughBROOKLYN | -1.1458556 | 0.0514892 | -22.254278 | 0.0000000 |
| boroughMANHATTAN | -1.0180213 | 0.0580792 | -17.528165 | 0.0000000 |
| boroughQUEENS | -0.3377869 | 0.0502914 | -6.716594 | 0.0000000 |
| boroughSTATEN ISLAND | -1.6359735 | 0.0995010 | -16.441776 | 0.0000000 |
| child_care_typeChild Care - Pre School | 0.1660567 | 0.0488473 | 3.399506 | 0.0006751 |
| maximum_capacity | 0.0023471 | 0.0003790 | 6.192338 | 0.0000000 |
As we can see in the summary, all predictors are significant with p value < 0.01, suggesting association with violation status. Different borough has different coefficients, suggesting regional difference in violation status. The odds of violation for childcare center in Bronx is 0.469, holding all other variables constant.For each of the other borough, the coefficient tells us that the log-odds of violation for a given group is smaller than that of the reference group.
We also used a simple method to test our model accuracy.Firstly, we split our dataset to training and testing dataset, and then fit the model using the training data, and test for accuracy using testing data. Lastly, I used confusion matrix to access our logistic model.
library(rsample) # for data splitting
# Modeling packages
library(caret) # for logistic regression modeling
# Model interpretability packages
library(vip) # variable importance
childcare_split <- initial_split(childcare_model, prop = .7)
childcare_train <- training(childcare_split)
childcare_test <- testing(childcare_split)
set.seed(123)
# predict violation using model
# fit logistic reg
logistic_model_train = childcare_train %>%
glm(violation_category ~ borough + child_care_type + maximum_capacity, data = ., family = binomial())
logistics_predict = predict(logistic_model_train, childcare_test, type = 'response')
# convert predicted value to TRUE/FALSE
childcare_test$predict_violation = ifelse(logistics_predict >= .5, 1, 0)
# Used confusion matrix to measure model performance
confusion_data = childcare_test %>%
select(predict_violation, violation_category) %>%
mutate(predict_violation = as.factor(predict_violation),
violation_category = as.factor(violation_category))
confusionMatrix(data=confusion_data$predict_violation, reference = confusion_data$violation_category) %>%
broom::tidy() %>%
select(term, estimate) %>%
filter(term %in% c("accuracy", "kappa", "sensitivity", "specificity", "f1")) %>%
knitr::kable(caption = "Measuring Model Performance ")| term | estimate |
|---|---|
| accuracy | 0.6202091 |
| kappa | 0.2390718 |
| sensitivity | 0.5913002 |
| specificity | 0.6475373 |
| f1 | 0.6020930 |
It turns out that our model has accuracy rate of 62%, with Kappa coefficient at around 0.24. This means that the predictability of our model is relatively week. But the significance of our predictors indicating that borough, childcare types and maximum capacity are all associated with violation. The reason behind regional disparities in violation should be investigated in the future.
Discussion
We expected that there would be a relationship between the boroughs and the categories of violation cases. After we analyzed the data for the study of violation cases by borough, we confirmed our idea, and the results showed that Queens was the borough with the highest number of violation cases, especially in the preschool program, while Staten Island had the lowest number of violation cases. Brooklyn performed relatively well because his violation record was much lower than the no-violation record. The Bronx underperforms because its number of violations is 2.5 times higher than its no-violation record. In Manhattan, a childcare provider’s violation record is essentially equivalent to a no-violation record. Therefore, we recommend that parents avoid sending their children to childcare centers in the Bronx and Queens, and if they have to, they must ensure that the quality and safety of the centers are satisfactory. Parents should choose relatively safe areas, such as Staten Island, whenever possible. In addition, the ANOVA results of the statistical analysis showed significant differences between the two variables. There are still a significant number of violation cases between the different boroughs. The New York City government should strengthen the regulation, especially the standards and quality of child care centers in the Bronx and Queens, to ensure a healthy environment for children to grow up in and balance the standards between the different boroughs in New York City. Specifically, “Beans Talk Childcare Academy” has the highest violation frequency of 189, “Noreast Bronx Daycare” and “Children of America Queens” also have violation frequency larger than 100. For childcare centers with high frequency of violation, we should adopt strict penalty and try to avoid same violation in the future. This action could help the parents rest assured to choose and trust the children’s health care center even in an unfamiliar borough or area.
Based on the graph of inspection categories versus violation categories, we found that the highest percentage of serious violations were found during the initial annual inspection, so parents should pay more attention to the initial annual inspection report when choosing a childcare provider for their child to ensure safety and reliability. We are pleased to see that the number of violations found in inspections of lead-based paint or water-containing lead is significantly less than in other inspections, but this statistic may also be due to undisciplined monitor. Therefore, we need to standardize such criteria to ensure that potential problems can be identified and addressed more effectively. Based on our top ten regulatory summaries of child care inspections, most of problems were due to inadequately maintained infrastructure, poorly qualified and unsupervised caregivers, and unsanitary environments. These issues are particularly risk factors for children because children attending these centers can’t protect themselves. Parents need to be more aware of these issues when choosing a childcare center. We expect those in charge of childcare centers with these problems to take responsibility for them. The government needs to provide more financial and technical support, as well as stricter monitoring and regulation of childcare centers that cannot address these issues on their own, to ensure that New York’s children live in a healthy and safe environment.
For our prediction model, although relatively weak predictability is observed for this logistic regression model with accuracy rate of 62% and Kappa coefficient at around 0.24, it suggested that borough, childcare type and maximum capacity are all connected with violation and could potentially be estimators of violation occurrence, which is consistent with our EDA. The main reason for our weak predictability is that, we lack of essential predictors for the model. Aiming at constructing a more accurate model, more related variables should be taken into consideration to refine violation prediction. Combined with the top 10 violation summary we analyzed before, useful predictors may include: hours of training, celling and floor maintance frequecny, stuff medical clearance status, etc. This can also be used as a guide for parents when selecting childcare center.
Our map assists parents in determining the quality of child care centers in different areas with the smallest unit of zipcode. However, since our map aggregates the number of violation in each area, parents should look for more updated and detailed information before selecting one.
There are several limitations we encountered in our research. The major challenge would be the target variables determination. There are several columns we thought we could use as our target numerical variables. But after we analysis, we found that “violation rate percent”, “public health hazard violation rate”, “average public health hazard violation”, “critical violation rate” and “average critical violation rate” are categorical number data which limits our data analysis part.
Additionally, for the map part, we want to map the violation cases in each children care center in NYC. It can represent the data more precise. But for our data set, it doesn’t have the latitude and longitude which make us hard to map as point units to determine the location.